Note
Click here to download the full example code
Train, convert and predict with ONNX Runtime¶
This example demonstrates an end to end scenario starting with the training of a machine learned model to its use in its converted from.
Train a logistic regression¶
The first step consists in retrieving the iris datset.
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
Then we fit a model.
from sklearn.linear_model import LogisticRegression
clr = LogisticRegression()
clr.fit(X_train, y_train)
We compute the prediction on the test set and we show the confusion matrix.
from sklearn.metrics import confusion_matrix
pred = clr.predict(X_test)
print(confusion_matrix(y_test, pred))
[[ 9 0 0]
[ 0 12 0]
[ 0 1 16]]
Conversion to ONNX format¶
We use module sklearn-onnx to convert the model into ONNX format.
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
initial_type = [("float_input", FloatTensorType([None, 4]))]
onx = convert_sklearn(clr, initial_types=initial_type)
with open("logreg_iris.onnx", "wb") as f:
f.write(onx.SerializeToString())
We load the model with ONNX Runtime and look at its input and output.
import onnxruntime as rt
sess = rt.InferenceSession("logreg_iris.onnx", providers=rt.get_available_providers())
print("input name='{}' and shape={}".format(sess.get_inputs()[0].name, sess.get_inputs()[0].shape))
print("output name='{}' and shape={}".format(sess.get_outputs()[0].name, sess.get_outputs()[0].shape))
input name='float_input' and shape=[None, 4]
output name='output_label' and shape=[None]
We compute the predictions.
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
import numpy
pred_onx = sess.run([label_name], {input_name: X_test.astype(numpy.float32)})[0]
print(confusion_matrix(pred, pred_onx))
[[ 9 0 0]
[ 0 13 0]
[ 0 0 16]]
The prediction are perfectly identical.
Probabilities¶
Probabilities are needed to compute other relevant metrics such as the ROC Curve. Let’s see how to get them first with scikit-learn.
prob_sklearn = clr.predict_proba(X_test)
print(prob_sklearn[:3])
[[9.74792469e-01 2.52074267e-02 1.04082095e-07]
[2.04372454e-08 3.27727275e-03 9.96722707e-01]
[3.58622821e-01 6.39558909e-01 1.81826980e-03]]
And then with ONNX Runtime. The probabilies appear to be
prob_name = sess.get_outputs()[1].name
prob_rt = sess.run([prob_name], {input_name: X_test.astype(numpy.float32)})[0]
import pprint
pprint.pprint(prob_rt[0:3])
[{0: 0.97479248046875, 1: 0.02520740032196045, 2: 1.0408190576072229e-07},
{0: 2.043722346911636e-08, 1: 0.0032772724516689777, 2: 0.9967227578163147},
{0: 0.35862284898757935, 1: 0.6395589113235474, 2: 0.0018182684434577823}]
Let’s benchmark.
from timeit import Timer
def speed(inst, number=10, repeat=20):
timer = Timer(inst, globals=globals())
raw = numpy.array(timer.repeat(repeat, number=number))
ave = raw.sum() / len(raw) / number
mi, ma = raw.min() / number, raw.max() / number
print("Average %1.3g min=%1.3g max=%1.3g" % (ave, mi, ma))
return ave
print("Execution time for clr.predict")
speed("clr.predict(X_test)")
print("Execution time for ONNX Runtime")
speed("sess.run([label_name], {input_name: X_test.astype(numpy.float32)})[0]")
Execution time for clr.predict
Average 8.19e-05 min=7.17e-05 max=0.000104
Execution time for ONNX Runtime
Average 3.77e-05 min=3.46e-05 max=4.94e-05
3.7683185000219054e-05
Let’s benchmark a scenario similar to what a webservice experiences: the model has to do one prediction at a time as opposed to a batch of prediction.
def loop(X_test, fct, n=None):
nrow = X_test.shape[0]
if n is None:
n = nrow
for i in range(0, n):
im = i % nrow
fct(X_test[im : im + 1])
print("Execution time for clr.predict")
speed("loop(X_test, clr.predict, 100)")
def sess_predict(x):
return sess.run([label_name], {input_name: x.astype(numpy.float32)})[0]
print("Execution time for sess_predict")
speed("loop(X_test, sess_predict, 100)")
Execution time for clr.predict
Average 0.00675 min=0.00645 max=0.00818
Execution time for sess_predict
Average 0.00192 min=0.00178 max=0.0025
0.0019168183650000968
Let’s do the same for the probabilities.
print("Execution time for predict_proba")
speed("loop(X_test, clr.predict_proba, 100)")
def sess_predict_proba(x):
return sess.run([prob_name], {input_name: x.astype(numpy.float32)})[0]
print("Execution time for sess_predict_proba")
speed("loop(X_test, sess_predict_proba, 100)")
Execution time for predict_proba
Average 0.00959 min=0.00917 max=0.0106
Execution time for sess_predict_proba
Average 0.00197 min=0.00189 max=0.00221
0.001971747110000308
This second comparison is better as ONNX Runtime, in this experience, computes the label and the probabilities in every case.
Benchmark with RandomForest¶
We first train and save a model in ONNX format.
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
initial_type = [("float_input", FloatTensorType([1, 4]))]
onx = convert_sklearn(rf, initial_types=initial_type)
with open("rf_iris.onnx", "wb") as f:
f.write(onx.SerializeToString())
We compare.
sess = rt.InferenceSession("rf_iris.onnx", providers=rt.get_available_providers())
def sess_predict_proba_rf(x):
return sess.run([prob_name], {input_name: x.astype(numpy.float32)})[0]
print("Execution time for predict_proba")
speed("loop(X_test, rf.predict_proba, 100)")
print("Execution time for sess_predict_proba")
speed("loop(X_test, sess_predict_proba_rf, 100)")
Execution time for predict_proba
Average 1.14 min=1.12 max=1.18
Execution time for sess_predict_proba
Average 0.00248 min=0.00229 max=0.00335
0.002478402585000481
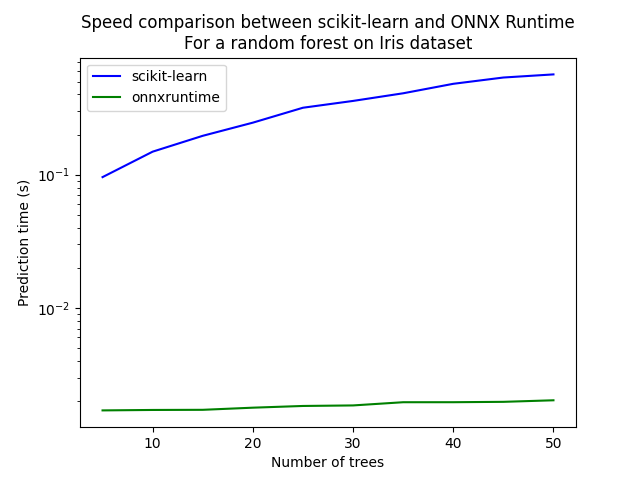
Let’s see with different number of trees.
measures = []
for n_trees in range(5, 51, 5):
print(n_trees)
rf = RandomForestClassifier(n_estimators=n_trees)
rf.fit(X_train, y_train)
initial_type = [("float_input", FloatTensorType([1, 4]))]
onx = convert_sklearn(rf, initial_types=initial_type)
with open("rf_iris_%d.onnx" % n_trees, "wb") as f:
f.write(onx.SerializeToString())
sess = rt.InferenceSession("rf_iris_%d.onnx" % n_trees, providers=rt.get_available_providers())
def sess_predict_proba_loop(x):
return sess.run([prob_name], {input_name: x.astype(numpy.float32)})[0]
tsk = speed("loop(X_test, rf.predict_proba, 100)", number=5, repeat=5)
trt = speed("loop(X_test, sess_predict_proba_loop, 100)", number=5, repeat=5)
measures.append({"n_trees": n_trees, "sklearn": tsk, "rt": trt})
from pandas import DataFrame
df = DataFrame(measures)
ax = df.plot(x="n_trees", y="sklearn", label="scikit-learn", c="blue", logy=True)
df.plot(x="n_trees", y="rt", label="onnxruntime", ax=ax, c="green", logy=True)
ax.set_xlabel("Number of trees")
ax.set_ylabel("Prediction time (s)")
ax.set_title("Speed comparison between scikit-learn and ONNX Runtime\nFor a random forest on Iris dataset")
ax.legend()
5
Average 0.0958 min=0.0905 max=0.105
Average 0.0017 min=0.0016 max=0.00179
10
Average 0.149 min=0.147 max=0.15
Average 0.00171 min=0.00159 max=0.0018
15
Average 0.196 min=0.193 max=0.198
Average 0.00172 min=0.00162 max=0.00182
20
Average 0.246 min=0.243 max=0.248
Average 0.00178 min=0.00167 max=0.00193
25
Average 0.318 min=0.313 max=0.323
Average 0.00184 min=0.00173 max=0.00193
30
Average 0.358 min=0.352 max=0.364
Average 0.00185 min=0.00177 max=0.0019
35
Average 0.408 min=0.405 max=0.411
Average 0.00196 min=0.00187 max=0.00221
40
Average 0.481 min=0.477 max=0.484
Average 0.00196 min=0.00191 max=0.002
45
Average 0.536 min=0.524 max=0.547
Average 0.00197 min=0.00191 max=0.00207
50
Average 0.565 min=0.562 max=0.571
Average 0.00203 min=0.00195 max=0.00217
<matplotlib.legend.Legend object at 0x7f3f3bce87c0>
Total running time of the script: ( 5 minutes 17.899 seconds)